How to Install and Run Ollama with Docker
July 11, 2024 by Anuraj
Docker AI Ollama
In this blog post, we’ll learn how to install and run Ollama with Docker. Ollama is a platform designed to streamline the development, deployment, and scaling of machine learning models. It aims to simplify the entire lifecycle of machine learning projects by providing tools and services that help with data preparation, model training, and deployment.
Downloading Ollama
We can install the Ollama executable from https://ollama.com/ website. Since we are using Docker, we can do it without installing the Ollama executable. We can download the Ollama image using the following command - docker pull ollama/ollama or we can run the image directly which will download the docker image and run the container using the command - docker run -d -v ollamaModels:/root/.ollama -p 11434:11434 --name ollama ollama/ollama - we need to mount the volume so that we can store the models we downloaded. We can also set the absolute path for mounting the volume, if we want to store it in specific drive like this - docker run -d -v D:\OllamaModels:/root/.ollama -p 11434:11434 --name ollama ollama/ollama. Once the image downloaded, we can run it with the docker run command. We can see the docker ps command to see which all docker containers are running. We can also see it using the Docker desktop. We can browse http://localhost:11434 URL which will display an HTML page with a message - Ollama is running like this.
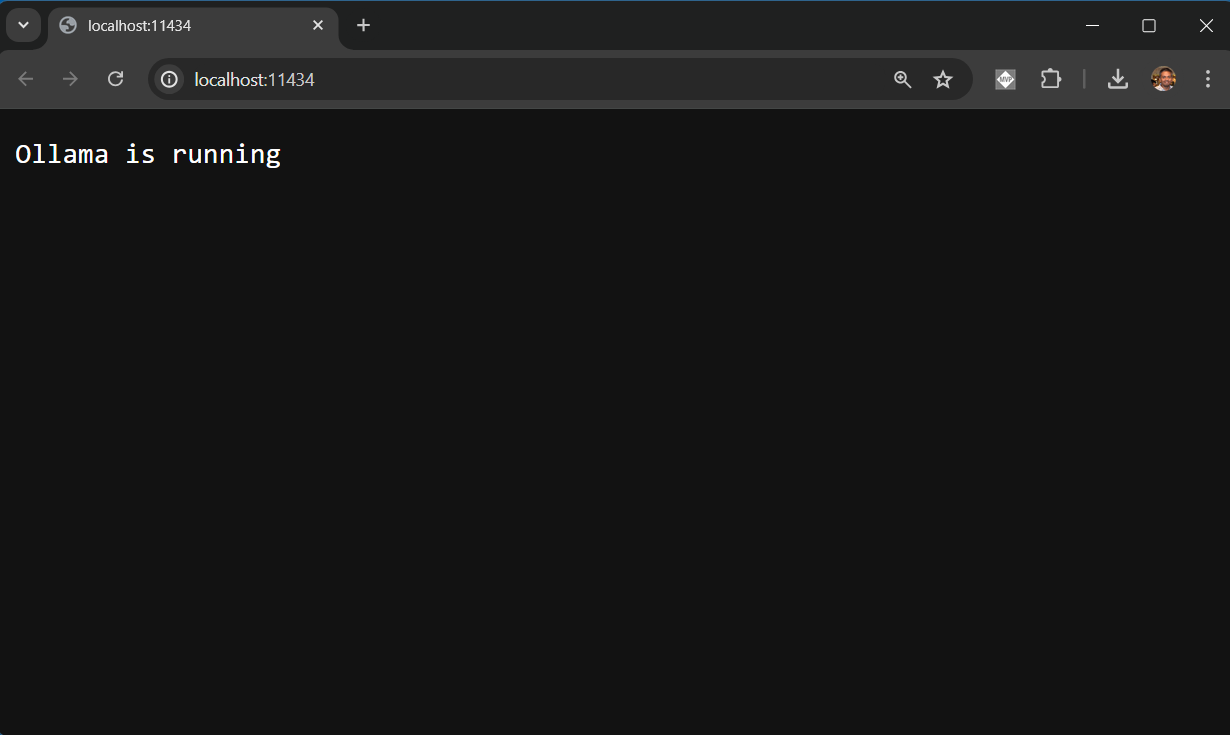
This the base URL for Ollama APIs as well.
Next we need to download and run models, we will explore it in the next section.
Downloading and running models
To download and run models, we can use ollama pull <model-name> and ollama run <model-name> commands. As we are working with Docker, we need to execute this command inside the container. We can see the downloaded models using ollama list command.
To run these commands inside the container, first we need to connect and execute bash terminal in Docker. We can do this using docker exec -it ollama bash - this command executes bash command in the container with name ollama interactively - the -it parameters. This will execute bash terminal in the container. Next we can execute the ollama commands. I am downloading the phi3 model from ollama library - https://ollama.com/library. This repository contains various models supported by ollama.
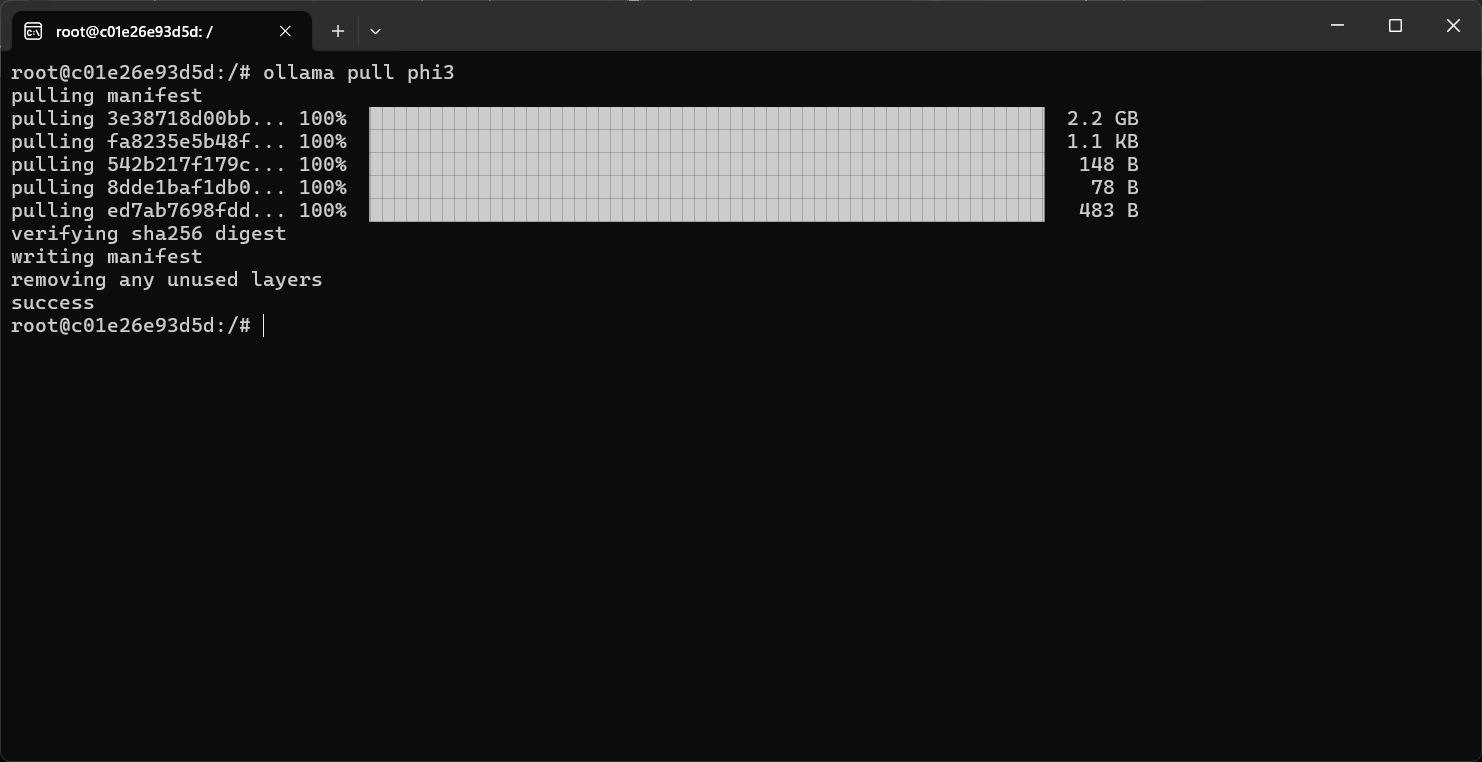
In the terminal, run the command ollama pull phi3 - this command will pull the phi3 model to our local machine. This command will may take some time depends the internet connection speed.
Once the pull command completed, we can execute ollama list command see the models.
Working with the phi3 model
We can work with the phi3 model by running it using ollama run phi3 command. Here is an example.
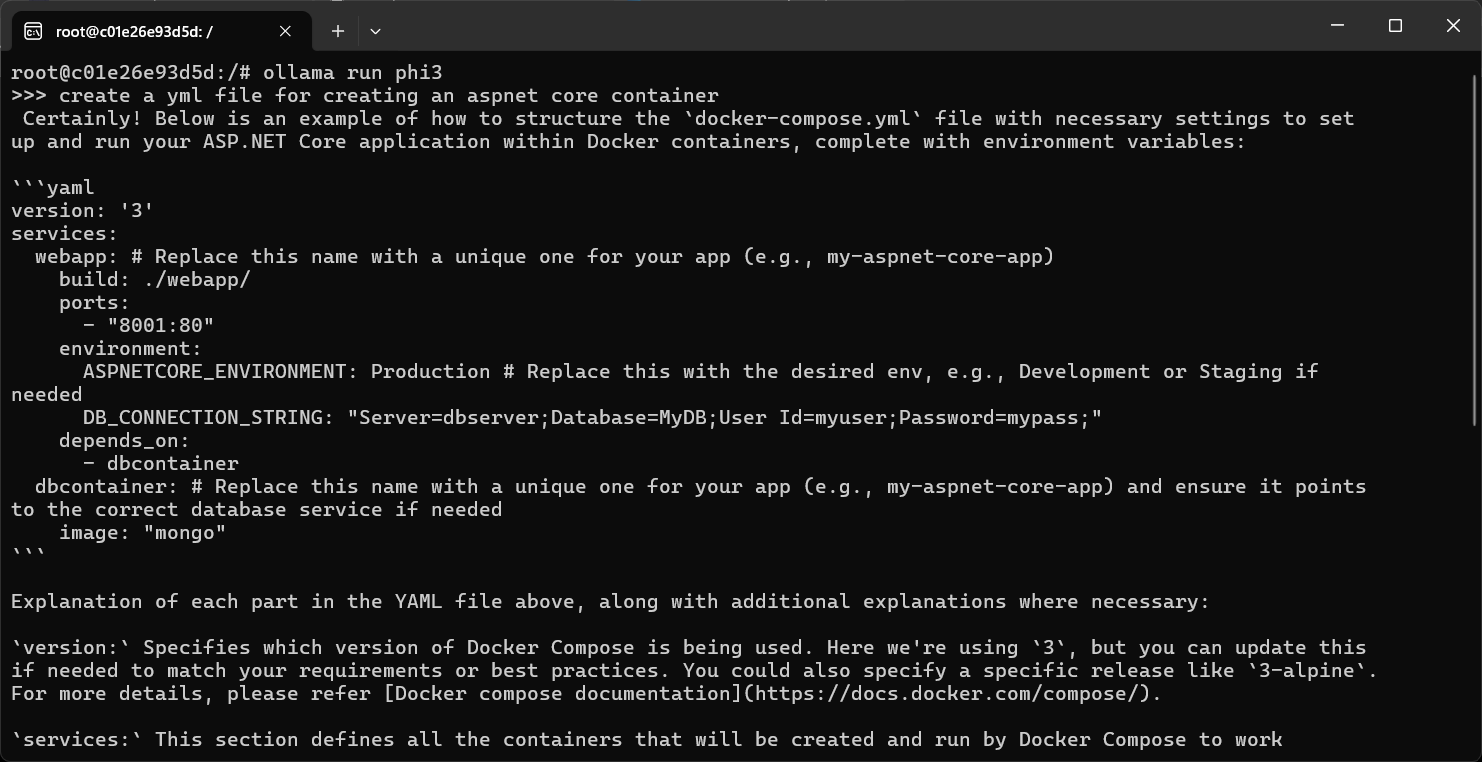
Once the command completes, we can say the command /bye command to exit from the phi3 model and exit command to exit from the bash terminal.
This way we can work with LLMs locally using Ollama and Docker. In the next few posts we will explore how to install the Web UI component for Ollama and how to connect to phi3 model from ASP.NET Core web application. Explore it and let me know if you have any questions / feedback.
Happy Programming
If you find my content helpful, consider supporting my work. Your support helps me continue creating valuable resources for the community.

Found this useful? Share it with your network!
Copyright © 2026 Anuraj. Blog content licensed under the Creative Commons CC BY 2.5 | Unless otherwise stated or granted, code samples licensed under the MIT license. This is a personal blog. The opinions expressed here represent my own and not those of my employer. Powered by Jekyll. Hosted with ❤ by GitHub