Running Open Web UI locally with Ollama
July 13, 2024 by Anuraj
Docker AI Ollama
In this blog post, we’ll learn how to install and run Open Web UI using Docker. Open WebUI is an extensible, feature-rich, and user-friendly self-hosted WebUI designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs.
Downloading the Open Web UI Docker image
As we are already downloaded Ollama image and phi3 model, we can download the Open Web UI docker image from their GitHub repo, by running the command - docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -e WEBUI_AUTH=false -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main - This command will run the docker image - open web ui with port 8080 in the host machine map to 3000 in the docker image. The volume mount is also required. The command parameter --add-host=host.docker.internal:host-gateway in docker run is used to add an entry to the container’s /etc/hosts file. Specifically, it maps the hostname host.docker.internal to the special Docker host gateway IP address, host-gateway. This allows the container to communicate with the host machine using host.docker.internal as the hostname. The WEBUI_AUTH environment variable disables authentication.
Once the image downloaded, it will run the application. We can browse the application using http://localhost:3000/
The Open Web UI looks like this.
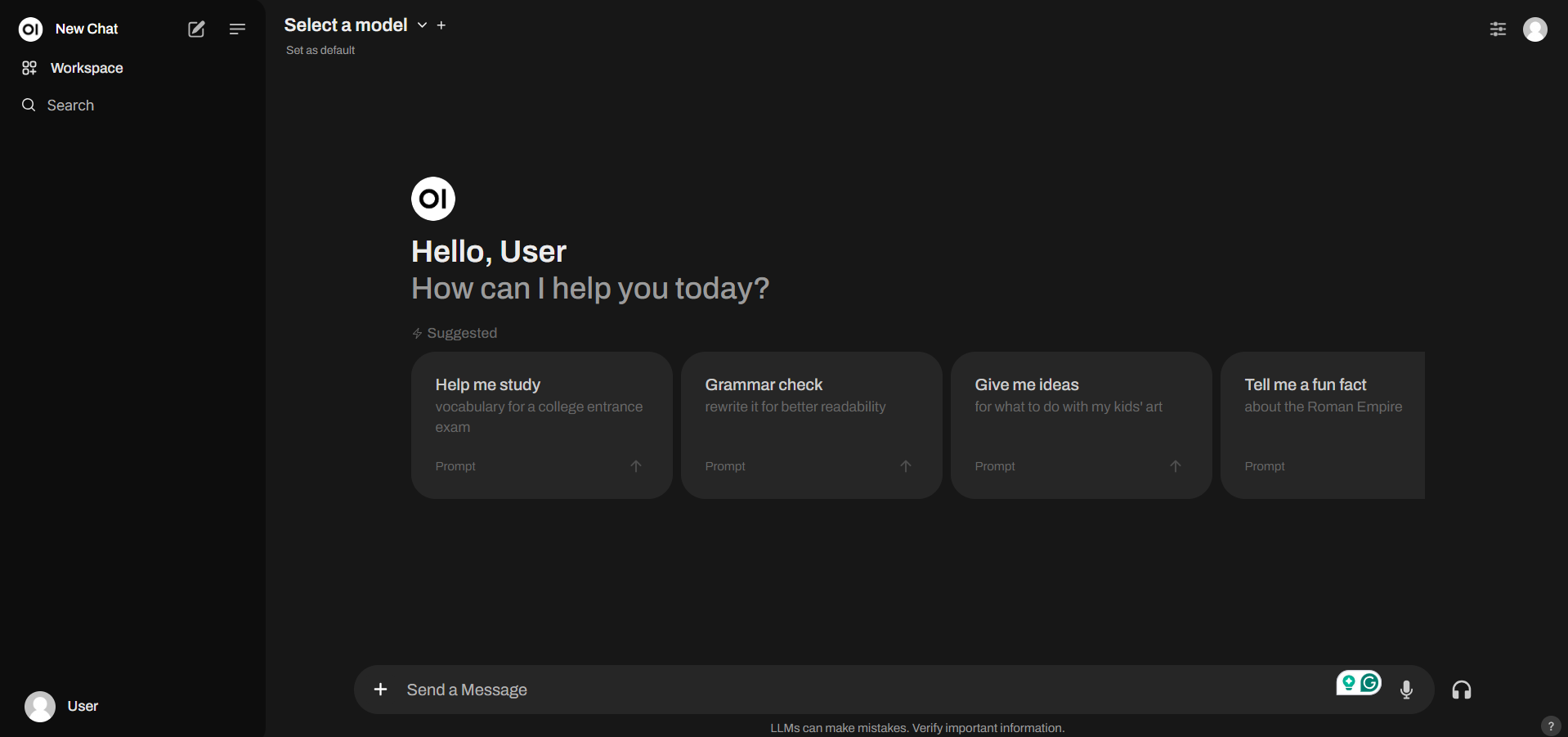
We can select the select phi3 from the select model in the UI and then we can interact with the phi3 model using chatgpt like interface.
We can download extra models using this interface too. In the select model option, we can search for a model and download it.
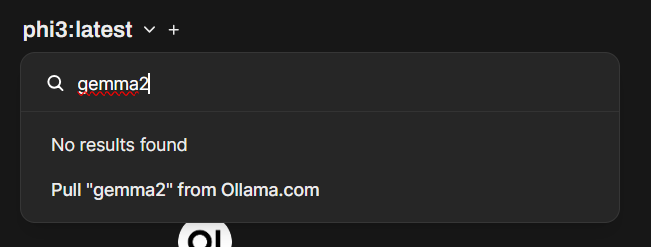
We can create a docker compose file and we can run both Ollama and Open Web UI together.
Running Ollama and Open Web UI with Docker compose
Here is the Docker compose file which runs both Ollama and Open Web UI image together.
services:
ollama:
image: ollama/ollama:latest
ports:
- 11434:11434
volumes:
- ollama:/root/.ollama
container_name: ollama
pull_policy: always
tty: true
restart: always
openwebui:
image: ghcr.io/open-webui/open-webui:main
ports:
- 3000:8080
container_name: openwebui
extra_hosts:
- "host.docker.internal:host-gateway"
environment:
- WEBUI_AUTH=false
- OLLAMA_BASE_URL=http://ollama:11434
restart: always
volumes:
- open-webui:/app/backend/data
depends_on:
- ollama
volumes:
ollama:
open-webui:Now we can run docker compose up --build command which will run both ollama and open web UI together. And we can browse the http://localhost:3000 URL and view the Open Web UI interface. We can run download the models using Open Web UI.
Downloading Phi3 models as part of docker compose process
To customize the model download process we need an external shell file. Here is the entrypoint.sh shell script file.
#!/bin/bash
/bin/ollama serve &
pid=$!
sleep 5
echo "Retrieve Phi3 model..."
ollama pull phi3
echo "Done!"
wait $pidIn the shell script I am executing the ollama serve command as a background process, waits for five seconds to simulate some delay before downloading the Phi model 3 (Phi3) language model. It uses echo statements at various stages to inform about progress or completion and utilizes wait with PID ($!) from earlier background processes as a safety measure ensuring that ollama serve doesn’t shut down before Phi3 is fully pulled, maintaining consistent accessibility during updates.
And we need to modify the docker compose file like this.
services:
ollama:
image: ollama/ollama:latest
ports:
- 11434:11434
volumes:
- ollama:/root/.ollama
- ./entrypoint.sh:/entrypoint.sh
container_name: ollama
pull_policy: always
tty: true
restart: always
entrypoint: [ "/usr/bin/bash", "/entrypoint.sh" ]
openwebui:
image: ghcr.io/open-webui/open-webui:main
ports:
- 3000:8080
container_name: openwebui
extra_hosts:
- "host.docker.internal:host-gateway"
environment:
- WEBUI_AUTH=false
- OLLAMA_BASE_URL=http://ollama:11434
restart: always
volumes:
- open-webui:/app/backend/data
depends_on:
- ollama
volumes:
ollama:
open-webui:In this Docker compose file, I am mounting the entrypoint.sh to the docker container and I am setting it as the entrypoint, so when the container is running, it will execute the entrypoint.sh file instead of running ollama serve command.
This way we can work with LLMs locally using Ollama with Open Web UI in Docker. We can run a local version of chatgpt with an implementation like this. In the next post we will explore how to connect to phi3 model from ASP.NET Core web application. Explore it and let me know if you have any questions / feedback.
Happy Programming
If you find my content helpful, consider supporting my work. Your support helps me continue creating valuable resources for the community.

Found this useful? Share it with your network!
Copyright © 2026 Anuraj. Blog content licensed under the Creative Commons CC BY 2.5 | Unless otherwise stated or granted, code samples licensed under the MIT license. This is a personal blog. The opinions expressed here represent my own and not those of my employer. Powered by Jekyll. Hosted with ❤ by GitHub